Альфа-бета алгоритм: эффективная реализация минимаксного принципа
Программа, показанная на рис. 15.3, производит просмотр в глубину дерева поиска, систематически обходя все содержащиеся в нем позиции вплоть до терминальных; она вычисляет статические оценки всех терминальных позиций. Как правило, для того, чтобы получить правильную минимаксную оценку корневой вершины, совсем не обязательно проделывать эту работу полностью. Поэтому алгоритм поиска можно сделать более экономным. Его можно усовершенствовать, используя следующую идею. Предположим, что у нас есть два варианта хода. Как только мы узнали, что один из них явно хуже другого, мы можем принять правильное решение, не выясняя, на сколько в точности он хуже. Давайте используем этот принцип для сокращения дерева поиска рис. 15.2. Процесс поиска протекает следующим образом:
(1) Начинаем с позиции а.
(2) Переходим к b.
(3) Переходим к d.
(4) Берем максимальную из оценок преемников позиции d, получаем V( d) = 4.
(5) Возвращаемся к b и переходим к е.
(6) Рассматриваем первого преемника позиции е с оценкой 5. В этот момент МАКС (который как раз и должен ходить в позиции е) обнаруживает, что ему гарантирована в позиции е оценка не меньшая, чем 5, независимо от оценок других (возможно, более предпочтительных) вариантов хода. Этого вполне достаточно для того, чтобы МИН, даже не зная точной оценки позиции е, понял, что для него в позиции b ход в е хуже, чем ход в d.
На основании приведенного выше рассуждения мы можем пренебречь вторым преемником позиции е
и приписать е приближенную оценку 5.
Приближенный характер этой оценки не окажет никакого влияния на оценку позиции b, а следовательно, и позиции а.
На этой идее основан знаменитый альфа-бета алгоритм, предназначенный для эффективной реализации минимаксного принципа. На рис. 15.4 показан результат работы альфа-бета алгоритма, примененного к нашему дереву рис. 15.2. Из рис. 15.4 видно, что некоторые из рабочих оценок стали приближенными. Однако этих приближенных оценок оказалось достаточно для того, чтобы определить точную оценку корневой позиции. Сложность поиска уменьшилась до пяти обращений к оценочной функции по сравнению с восемью обращениями (в первоначальном дереве поиска рис. 15.2).
Как уже говорилось раньше, ключевая идея альфа-бета отсечения состоит в том, чтобы найти ход не обязательно лучший, но "достаточно хороший" для того, чтобы принять правильное решение. Эту идею можно формализовать, введя два граничных значения, обычно обозначаемых через Альфа
и Бета, между которыми должна заключаться рабочая оценка позиции. Смысл этих граничных значений таков: Альфа -это самое маленькое значение оценки, которое к настоящему моменту уже гарантировано для игрока МАКС; Бета - это самое большое значение оценки, на которое МАКС пока еще может надеяться. Разумеется, с точки зрения МИН'а, Бета является самым худшим значением оценки, которое для него уже гарантировано. Таким образом, действительное значение оценки (т. е. то, которое нужно найти) всегда лежит между Альфа и Бета. Если же стало известно, что оценка некоторой позиции лежит вне интервала Альфа-Бета, то этого достаточно для того, чтобы сделать вывод: данная позиция не входит в основной вариант. При этом точное значение оценки такой позиции знать не обязательно, его надо знать только тогда, когда оценка лежит между Альфа и Бета. "Достаточно хорошую" рабочую оценку V( Р, Альфа, Бета) позиции Р по отношению к Альфа и Бета можно определить формально как любое значение, удовлетворяющее следующим ограничениям:
V( P, Альфа, Бета) <= Альфа если V( P) <= Альфа
V( P, Альфа, Бета) = V( P)
если Альфа < V( P) < Бета
V( P, Альфа, Бета) >= Бета если V( P) >= Бета
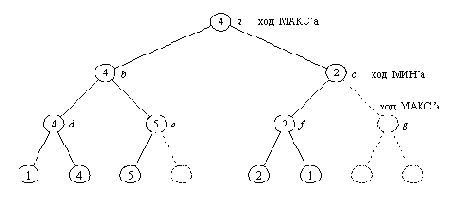
Рис. 15. 4. Дерево рис. 15.2 после применения альфа-бета алгоритма.
Пунктиром показаны ветви, отсеченные альфа-бета алгоритмом
для экономии времени поиска. В результате некоторые из
рабочих оценок стали приближенными (вершины c, е, f;
сравните с рис.15.2). Однако этих приближенных оценок
достаточно для вычисления точной оценки корневой
вершины и построения основного варианта.
Очевидно, что, умея вычислять "достаточно хорошую" оценку, мы всегда можем вычислить точную оценку корневой позиции Р, установив границы интервала следующим образом:
V( Р, -бесконечность, +бесконечность) = V( P)
На рис. 15.5 показана реализация альфа-бета алгоритма в виде программы на Прологе. Здесь основное отношение -
альфабета( Поз, Альфа, Бета, ХорПоз, Оц)
где ХорПоз - преемник позиции Поз с "достаточно хорошей" оценкой Оц, удовлетворяющей всем указанным выше ограничениям:
Оц = V( Поз, Альфа, Бета)
Процедура
прибл_лучш( СписПоз, Альфа, Бета, ХорПоз, Оц)
находит достаточно хорошую позицию ХорПоз в списке позиций СписПоз; Оц - приближенная (по отношению к Альфа и Бета) рабочая оценка позиции ХорПоз.
Интервал между Альфа и Бета может сужаться (но не расширяться!) по мере углубления поиска, происходящего при рекурсивных обращениях к альфа-бета процедуре.
Отношение
нов_границы( Альфа, Бета, Поз, Оц, НовАльфа, НовБета)
определяет новый интервал (НовАльфа, НовБета). Он всегда уже, чем старый интервал (Альфа, Бета), или равен ему. Таким образом, чем глубже мы оказываемся в дереве поиска, тем сильнее проявляется тенденция к сжатию интервала Альфа-Бета, и в результате оценивание позиций на более глубоких уровнях происходит в условиях более тесных границ. При более узких интервалах допускается большая степень "приблизительности" при вычислении оценок, а следовательно, происходит больше отсечений ветвей дерева. Возникает интересный вопрос: насколько велика экономия, достигаемая альфа-бета алгоритмом по сравнению с программой минимаксного полного перебора рис. 15.3?
Эффективность альфа-бета процедуры зависит от порядка, в котором просматриваются позиции. Всегда лучше первыми рассматривать самые сильные ходы с каждой из сторон. Легко показать на примерах, что
line(); % Альфа-бета алгоритм
альфабета( Поз, Альфа, Бета, ХорПоз, Оц) :-
ходы( Поз, СписПоз), !,
прибл_лучш( СписПоз, Альфа, Бета, ХорПоз, Оц);
стат_оц( Поз, Оц).
прибл_лучш( [Поз | СписПоз], Альфа, Бета, ХорПоз, ХорОц) :-
альфабета( Поз, Альфа, Бета, _, Оц),
дост_хор( СписПоз, Альфа, Бета, Поз, Оц, ХорПоз, ХорОц).
дост_хор( [ ], _, _, Поз, Оц, Поз, Оц) :- !.
% Больше нет кандидатов
дост_хор( _, Альфа, Бета, Поз, Оц, Поз, Оц) :-
ход_мина( Поз), Оц > Бета, !;
% Переход через верхнюю границу
ход_макса( Поз), Оц < Альфа, !.
% Переход через нижнюю границу
дост_хор( СписПоз, Альфа, Бета, Поз, Оц, ХорПоз, ХорОц) :-
нов_границы( Альфа, Бета, Поз, Оц, НовАльфа, НовБета),
% Уточнить границы
прибл_лучш( СписПоз, НовАльфа, НовБета, Поз1, Оц1),
выбор( Поз, Оц, Поз1, Оц1, ХорПоз, ХорОц).
нов_границы( Альфа, Бета, Поз, Оц, Оц, Бета) :-
ход_мина( Поз), Оц > Альфа, !.
% Увеличение нижней границы
нов_границы( Альфа, Бета, Поз, Оц, Альфа, Оц) :-
ход_макса( Поз), Оц < Бета, !.
% Уменьшение верхней границы
нов_границы( Альфа, Бета, _, _, Альфа, Бета).
выбор( Поз, Оц, Поз1, Оц1, Поз, Оц) :-
ход_мина( Поз), Оц > Оц1, !;
ход_макса( Поз), Оц < Оц1, !.
выбор( _, _, Поз1, Оц1, Поз1, Оц1).
line(); Рис. 15. 5. Реализация альфа-бета алгоритма.
возможен настолько неудачный порядок просмотра, что альфа-бета алгоритму придется пройти через все вершины, которые просматривались минимаксным алгоритмом полного перебора. Это означает, что в худшем случае альфа-бета алгоритм не будет иметь никаких преимуществ. Однако, если порядок просмотра окажется удачным, то экономия может быть значительной. Пусть N - число терминальных поисковых позиций, для которых вычислялись статические оценки алгоритмом минимаксного полного перебора. Было доказано, что в лучшем случае, когда самые сильные ходы всегда рассматриваются первыми, альфа-бета алгоритм вычисляет статические оценки только для N позиций.
Этот результат имеет один практический аспект, связанный с проведением турниров игровых программ. Шахматной программе, участвующей в турнире, обычно дается некоторое определенное время для вычисления очередного хода, и доступная программе глубина поиска зависит от этого времени. Альфа-бета алгоритм сможет пройти при поиске вдвое глубже по сравнению с минимаксным полным перебором, а опыт показывает, что применение той же оценочной функции, но на большей глубине приводит к более сильной игре.
Экономию, получаемую за счет применения альфа-бета алгоритма, можно также выразить в терминах более эффективного коэффициента ветвления дерева поиска (т. е. числа ветвей, исходящих из каждой внутренней вершины). Пусть игровое дерево имеет единый коэффициент ветвления, равный b. Благодаря эффекту отсечения альфа-бета алгоритм просматривает только некоторые из существующих ветвей и тем самым уменьшает коэффициент ветвления. В результате коэффициент b превратится в b (в лучшем случае). В шахматных программах, использующих альфа-бета алгоритм, достигается коэффициент ветвления, равный 6, при наличии 30 различных вариантов хода в каждой позиции. Впрочем, на этот результат можно посмотреть и менее оптимистично: несмотря на применение альфа-бета алгоритма, после каждого продвижения вглубь на один полуход число терминальных поисковых вершин увеличивается примерно в 6 раз.